Последнее время я все больше укрепляюсь в давно блуждающей в моей голове и довольно еретической мысли: классический показатель доступности малопригоден для измерения и оценки доступности ИТ-услуг в реальном мире. И в ряде случаев от него можно легко отказаться. Эти случаи касаются в первую очередь измерения доступности услуг типа « » (фактически речь идет об ИТ-доступности бизнес-процессов). Попробую обосновать и буду рад услышать возражения.
Полагаю, всем читателям портала знакома формула:
Availability = (AST — DT)/AST ,
где AST - согласованное время предоставления услуги, DT - сумма простоев за период.
А также, вероятно, знакомы сложности ее применения:
Первая сложность связана с обсуждением показателя. Доступность определена как 99,9%. Вроде неплохо. Но 0,1% в год равен почти 9 часам. А в месяц - это почти 45 минут. А в неделю - чуть более 10 минут. Так какие 99,9% имел в виду заказчик? А сервис-провайдер?
Однако значительно более существенен следующий нюанс: показатель довольно неточно отражает негативное влияние на бизнес. Что если все без малого 9 часов за год случились разом? Или услуга становилась недоступна потребителям по две минуты, но 15 раз за один день? Как это будет выражено в процентах?.. Поэтому, например, ITIL вводит такие показатели, как MTRS, MTBF, MTBSI.
Однако предлагаю вернуться в начало координат и задаться вопросом, а зачем мы вообще вводим показатели доступности? Почему бизнес предъявляет требования к доступности услуг? Почему сервис-провайдер должен обеспечивать высокую доступность и отчитываться по ее фактическим значениям? Ответ прост: бизнес несет потери вследствие простоев ИТ-услуг. Значит, идеальным для бизнеса показателем доступности, вероятно, была бы метрика «Потери вследствие простоев ИТ-услуг»?
Сильно выручила бы такая метрика и сервис-провайдера. Ведь это готовый ответ на вопрос о бизнес-рисках, связанных с нарушениями ИТ-доступности. И, следовательно, у сервис-провайдера появляется возможность:
- более прозрачно транслировать требования доступности бизнес-процессов к ИТ-инфраструктуре;
- более обоснованно принимать решения по мерам, направленным на повышение надежности и отказоустойчивости ИТ-систем;
- более обоснованно оценивать успешность мер по итогам их реализации.
Но, конечно, произвести расчет такой метрики сложно, порой невозможно. Таким образом, мы должны определить другие показатели, не забывая о том, что в совокупности они должны нести информацию о бизнес-влиянии (фактическом или потенциальном).
От чего зависят потери бизнеса вследствие простоев?
- Чем меньше за отчетный период услуга была в uptime, тем больше потери. Введем показатель «Суммарное время простоев».
- Чем дольше разовый простой, тем больше потери. Нередко потери не являются постоянной во времени величиной и зависят от длительности прерывания экспоненциально. В первый отрезок времени ущерб складывается из несовершенных транзакций, потерь продуктивности персонала и затрат на восстановление, но с определенного момента длительный простой угрожает бизнесу штрафами, санкциями, уроном репутации и так далее. Введем показатель «Максимальный разовый простой».
- Ряд бизнес-процессов, напротив, «чувствительны» не к единичным длительным простоям, а к частым прерываниям. Это особенно важный фактор для процессов, в рамках которых происходят длительные вычисления, которые в случае прерывания требуется перезапускать. Таким образом, должно быть обеспечено как можно меньшее количество прерываний за период. Введем показатель «Количество нарушений».
Альтернативной (или дополнительной) метрикой, отражающей тот же аспект, но с акцентом на периоде спокойной работы пользователей, может быть показатель «Минимальная (или средняя) продолжительность работы без нарушений».
Представленные показатели в совокупности, кажется, отражают характер того, как бизнес несет потери вследствие простоев ИТ-услуг. Поэтому далее остается только известным способом выполнить нормирование и агрегирование. Да, полученный показатель будет также выражен в процентах, но это будут уже совсем другие проценты.
При этом не обязательно для каждой ИТ-услуги использовать все три (или четыре) метрики. В зависимости от того, чувствителен ли бизнес к частым нарушениям данной ИТ-услуги или, напротив, для него критичны длительные разовые нарушения, часть показателей могут быть опущены или включены в расчет с меньшим весом.
От представленных метрик можно легко перейти к известным MTRS, MTBF, MTBSI и, конечно, классическому показателю доступности. Но, на мой взгляд, предложенный набор скажет заказчику и сервис-провайдеру несколько больше о бизнес-влиянии нарушений ИТ-доступности. Или нет?
Отчаянно нуждаюсь в возражениях. Почему от классического показателя доступности услуги, выраженной в процентах, ни в коем случае нельзя отказываться? Есть ли такой показатель в ваших отчетах? О чем и кому он говорит?
Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности .
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.- Отказоустойчивость (Fault Tolerance, FT) - способность системы к дальнейшей работе после выхода из строя какого-либо её элемента.
- Кластер - группа серверов (вычислительных единиц), объединенных каналами связи.
- Отказоустойчивый кластер (Fault Tolerant Cluster, FTC) - кластер, отказ сервера в котором не приводит к полной неработоспособности всего кластера. Задачи вышедшей из строя машины распределяются между одной или несколькими оставшимися нодами в автоматическом режиме.
- Непрерывная доступность (Continuous Availability, CA) - пользователь может в любой момент воспользоваться сервисом, перерывов в предоставлении не происходит. Сколько времени прошло с момента отказа узла не имеет значения.
- Высокая доступность (High Availability, HA) - в случае выхода из строя узла пользователь какое-то время не будет получать услугу, однако восстановление системы произойдёт автоматически; время простоя минимизируется.
- КНД - кластер непрерывной доступности, CA-кластер.
- КВД - кластер высокой доступности, HA-кластер.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Аппаратный способ
представляет собой “раздвоенный” сервер: все компоненты дублированы, а вычисления выполняются одновременно и независимо. За синхронность отвечает узел, который в числе прочего сверяет результаты с половинок. В случае несоответствия выполняется поиск причины и попытка коррекции ошибки. Если ошибка не корректируется, то неисправный модуль отключается.
На Хабре недавно была на тему аппаратных CA-серверов. Описываемый в материале производитель гарантирует, что годовое время простоя не более 32 секунд. Так вот, для того чтобы добиться таких результатов, надо приобрести оборудование. Российский партнёр компании Stratus сообщил, что стоимость CA-сервера с двумя процессорами на каждый синхронизированный модуль составляет порядка $160 000 в зависимости от комплектации. Итого на кластер потребуется $1 600 000.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности - от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
- На физическом хосте должен быть процессор:
- Intel архитектуры Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
- Машины, на которых используется Fault Tolerance, должны быть объединены в 10-гигабитную сеть с низкими задержками. Компания VMware настоятельно рекомендует выделенную сеть.
- Не более 4 виртуальных процессоров на ВМ.
- Не более 8 виртуальных процессоров на физический хост.
- Не более 4 виртуальных машин на физический хост.
- Невозможно использовать снэпшоты виртуальных машин.
- Невозможно использовать Storage vMotion.
Экспериментально установлено, что технология Fault Tolerance от VMware значительно “тормозит” виртуальную машину. В ходе исследования vmgu.ru после включения FT производительность ВМ при работе с базой данных упала на 47%.
Лицензирование vSphere привязано к физическим процессорам. Цена начинается с $1750 за лицензию + $550 за годовую подписку и техподдержку. Также для автоматизации управления кластером требуется приобрести VMware vCenter Server, который стоит от $8000. Поскольку для обеспечения непрерывной доступности используется схема 2N, для того чтобы работали 10 нод с виртуальными машинами, нужно дополнительно приобрести 10 дублирующих серверов и лицензии к ним. Итого стоимость программной части кластера составит 2 *(10 + 10)*(1750 + 550)+ 8000 =$100 000.
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый - Kemari , продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй - Micro Checkpointing , основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
- Вычислительный. К нему относятся ноды, на которых непосредственно запущены виртуальные машины
- Кластер хранилища. Тут находятся диски, которые используются нодами вычислительного подкластера.
- Heartbeat версии 1.х в связке с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- Openstack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- VMmanager Cloud.
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.В упрощённой форме алгоритм такой:
- Происходит поиск узла кластера с наименьшим количеством виртуальных машин.
- Выполняется запрос хватает ли свободной оперативной памяти для размещения текущей ВМ в списке.
- Если памяти для распределяемой машины достаточно, то VMmanager отдаёт команду на создание виртуальной машины на этом узле.
- Если памяти не хватает, то выполняется поиск на серверах, которые несут на себе большее количество виртуальных машин.
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Network LVM, iSCSI и Ceph . В контексте КВД используются последние три.
При использовании вечной лицензии стоимость программной части кластера из десяти “боевых” узлов и одного резервного составит €3520 или $3865 на сегодняшний день (лицензия стоит €320 за ноду независимо от количества процессоров на ней). В лицензию входит год бесплатных обновлений, а со второго года они будут предоставляться в рамках пакета обновлений стоимостью €880 в год за весь кластер.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:- Возможность предоставления виртуальных машин на KVM;
- Наличие интеграции с Ceph;
- Наличие интеграции с биллингом подходящим для предоставления имеющихся услуг;
- Доступная стоимость лицензий;
- Наличие поддержки производителя.
Отличительные черты кластера:
- Передача данных основана на технологии Ethernet и построена на оборудовании Cisco.
- За маршрутизацию отвечает Cisco ASR9001; в кластере используется порядка 50000 IPv6 адресов.
- Скорость линка между вычислительными нодами и коммутаторами 10 Гбит/с.
- Между коммутаторами и нодами хранилища скорость обмена данными 20 Гбит/с, используется агрегирование двух каналов по 10 Гбит/с.
- Между стойками с нодами хранилища есть отдельный 20-гигабитный линк, используемый для репликации.
- В узлах хранилища установлены SAS-диски в связке с SSD-накопителями.
- Тип хранилища - Ceph.

Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.К использованию VMmanager Cloud компания пришла из следующих соображений:
- Большой опыт работы с продуктами ISPsystem.
- Наличие интеграции с BILLmanager по умолчанию.
- Отличное качество техподдержки продуктов.
- Поддержка Ceph.
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Infiniband-сеть построена на оборудовании Mellanox;
- В узлах хранилища установлены SSD-носители;
- Используемый тип хранилища - Ceph.

В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки - не обойтись без кластера непрерывной доступности.Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости - избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать - резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя. Добавить метки
«Эталонные архитектуры максимальной доступности Oracle (Oracle Maximum Availability Architecture) Основа подхода DBaaS (база данных как сервис) ОФИЦИАЛЬНЫЙ ДОКУМЕНТ ORACLE | СЕНТЯБРЬ...»
Availability Architecture (MAA)
Эталонные архитектуры максимальной доступности
Oracle (Oracle Maximum Availability Architecture)
Основа подхода DBaaS (база данных как сервис)
ОФИЦИАЛЬНЫЙ ДОКУМЕНТ ORACLE | СЕНТЯБРЬ 2015
Введение 1
Эталонные архитектуры высокой доступности - обзор 2
Bronze: одиночный экземпляр 4 Высокая доступность и защита данных в Oracle Database 4 Консолидация баз данных на уровне Bronze 5 Управление жизненным циклом и предоставление базы данных как сервис (DBaaS) 5 Комплексы Oracle Engineered Systems 5 Заключение по уровню Bronze: защита данных, RTO и RPO 6 Silver: высокая доступность с автоматическим переключением на резерв 7 Oracle Real Application Clusters (Oracle RAC) 8 Oracle RAC One Node 8 Заключение по уровню Silver: защита данных, RTO и RPO 9 Gold: комплексные возможности высокой доступности и аварийного восстановления 9 Oracle Active Data Guard - защита данных в реальном времени и высокая доступность 10 Oracle GoldenGate 11 Oracle Site Guard 12 Заключение по уровню Gold: защита данных, RTO и RPO 13 Platinum: отсутствие простоев для приложений, готовых к уровню сервиса Platinum 14 Технология Application Continuity 14 Oracle Active Data Guard Far Sync 15
Техническое обслуживание без простоев с помощью GoldenGate и репликация «активный-активный» 15 Функция Edition Based Redefinition 16 Решение Oracle Global Data Services 16 Заключение по уровню Platinum: защита данных, RTO и RPO 17 Заключение 17ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Введение В современном мире компании испытывают сильное давление делать больше с меньшими затратами, снижать риски и повышать гибкость. Активная консолидация ИТ-технологий и развертывание DBaaS (база данных как сервис) в публичных и частных облаках - стратегия, к которой обращаются многие компании для достижения этой цели. Оба этих направления развития существенно влияют на разработку и внедрение архитектур для высокой доступности и защиты данных.В результате консолидации баз данных серьезно усугубляются проблемы простоев и потери данных. Последствия выхода из строя одной автономной среды, используемой одним разработчиком или небольшой рабочей группой, часто незначительны. Такой выход из строя консолидированной среды, поддерживающей весь коллектив разработчиков организации, или сбой множества приложений, используемых многими отделами, может нарушить работу компании. В этом примере уровни обслуживания, обеспечивающие высокую доступность и защиту данных консолидированной среды, гораздо важнее, чем прежние уровни обслуживания для автономных сред.
Для консолидации данных и подхода DBaaS также требуется стандартизация ИТ-услуг и процессов. Стандартизация - важное условие снижения расходов и сложности эксплуатации. При правильной стандартизации также может значительно повыситься гибкость организации, позволяя службам ИТ быстро реагировать на меняющиеся потребности бизнеса.
В архитектуре максимальной доступности Oracle (Oracle Maximum Availability Architecture) определены четыре эталонные архитектуры высокой доступности, которые обеспечивают нужный уровень стандартизации и одновременно решают весь комплекс проблем доступности и защиты данных в организациях любого размера и направления бизнеса.
В этой статье подробно рассмотрена каждая эталонная архитектура и соответствующие уровни обслуживания, которых можно достичь. Статья предназначена в основном для технических специалистов: архитекторов, директоров по ИТ и администраторов баз данных, ответственных за проектирование и внедрение подхода DBaaS. Рекомендованные лучшие практики одинаково подходят для любой платформы, которую поддерживает СУБД Oracle Database, если специально не указано, что данная оптимизация предназначена только для Oracle Engineered Systems.
1 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Эталонные архитектуры высокой доступности - обзор Лучшие практики Oracle MAA определяют четыре эталонные архитектуры высокой доступности, позволяющие полностью обеспечить доступность системы и защиту данных для организаций любых размеров и направлений бизнеса. Эти архитектуры или уровни высокой доступности обозначены как PLATINUM (ПЛАТИНОВЫЙ), GOLD (ЗОЛОТОЙ), SILVER (СЕРЕБРЯННЫЙ) И BRONZE (БРОНЗОВЫЙ).Они обеспечивают уровни обслуживания, описанные на рис. 1.
– – –
Рис. 1. Уровни обслуживания для высокой доступности и защиты данных На каждом уровне используется собственная эталонная архитектура MAA для развертывания оптимального набора средств высокой доступности Oracle, которые надежно обеспечат заданный уровень обслуживания с минимальными расходами и сложностью. Они решают проблемы любых внеплановых отключений, включая повреждение данных, отказ одного из компонентов, выход из строя системы или отключение центра обработки данных, а также плановых отключений для техобслуживания, миграции или других целей. Общее описание каждой архитектуры представлено на рис. 2.
Рис. 2. Эталонные архитектуры высокой доступности и защиты данных
Уровню Bronze соответствуют базы данных, где простой перезапуск или восстановление из резервной копии считается «достаточно высокой доступностью». Уровень Bronze основан на одиночном экземпляре СУБД Oracle Database и использует лучшие практики архитектуры MAA, которые включают множество средств защиты данных и высокой доступности, включенных в лицензию Oracle Enterprise Edition.
Резервные копии, оптимизированные Oracle с помощью Oracle Recovery Manager (RMAN), обеспечивают
2 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
защиту данных и используются для восстановления в случае, когда перезапуск базы данных невозможен.Уровень Silver обеспечивает дополнительную степень высокой доступности для баз данных, требующих минимального или нулевого простоя при выходе из строя экземпляра БД или сервера, а также для большинства видов планового простоя на обслуживание. Уровень Silver дополнен технологией кластеризации - Oracle RAC или RAC One Node. RMAN предоставляет резервные копии баз данных для защиты данных и восстановления доступности, если отключение делает перезапуск кластера невозможным.
Уровень Gold значительно повышает уровень обслуживания для критически важных бизнес-приложений, где отказ ни одного из компонентов не приводит к выходу из строя всей системы. Уровень Gold дополнен технологиями репликации баз данных: Active Data Guard и Oracle GoldenGate. Эти технологии синхронизируют одну или более реплик производственной базы данных для обеспечения защиты данных в реальном времени и высокой доступности. Репликация баз данных обеспечивает значительно более высокий уровень доступности и защиты данных, чем технологии репликации на уровне системы хранения. Она также снижает расходы и повышает выгоду от инвестиций благодаря постоянному активному использованию всех реплик.
Уровень Platinum предоставляет несколько новых возможностей Oracle Database 12c, а также ранее доступные продукты, расширенные в новой версии. В него включены технология Application Continuity для надежного повтора выполняемых транзакций, Active Data Guard Far Sync для полной защиты от потери данных при любом удалении реплики от основной БД, новые расширения GoldenGate для обновления и миграций без простоев и Global Data Services для автоматического управления и балансировкой нагрузки для репликаций БД. Хотя внедрение каждой из технологий требует значительных усилий, это обеспечивает значительные преимущества для критически важных приложений, где простои и потеря данных недопустимы.
В следующей таблице суммируются атрибуты высокой доступности (HA) и защиты данных, встроенные в каждую эталонную архитектуру.
ВЫСОКАЯ ДОСТУПНОСТЬ И ЗАЩИТА ДАННЫХ
– – –
Эталонные архитектуры MAA по своей сути предназначены для решения противоречивых задач.
С одной стороны, не у каждого приложения одни и те же требования высокой доступности и защиты данных. С другой стороны, стандартная архитектура - это эксплуатационное требование и обязательное условие для бизнеса, если требуется снизить сложность и расходы.
Эталонная архитектура MAA учитывает обе реальности и предоставляет инфраструктуру, которая оптимизирована для Oracle Database и позволяет задать нужный уровень HA для разных требований к уровню сервиса. Благодаря этому можно легко перенести базу данных на следующий уровень в случае изменения бизнес-требований или при
3 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
переходе с одной аппаратной платформы на другую.В следующих разделах каждая эталонная архитектура описывается более подробно.
Bronze: одиночный экземпляр Уровень Bronze предоставляет базовый сервис БД с самыми низкими расходами. Расходы и сложность внедрения снижаются за счет более низкого уровня доступности и защиты данных. На рис. 3 представлен общий вид уровня Bronze.
Уровень Bronze использует один экземпляр БД Oracle Database; никакая технология кластеризации не используется в случае отказа сервера для автоматического переключения на резерв, на котором есть работающий экземпляр Oracle Database. Если выходит из строя сервер или база данных, целевое время восстановления (RTO) зависит от того, насколько быстро можно предоставить другое оборудование на замену или выполнить восстановление из резервной копии. В худшем сценарии полного отключения вычислительной площадки потребуется дополнительное время для выполнения этих задач на резервном узле, и в некоторых случаях на это могут потребоваться дни.
Уровень Bronze: одиночный экземпляр RTO от минут до дней, RPO со времени последнего резервного копирования Рис. 3. Эталонная архитектура высокой доступности Bronze Oracle Recovery Manager (RMAN) используется для регулярного резервного копирования СУБД Oracle Database.
Возможная потеря данных, называемая целевой точкой восстановления (RPO), - это все данные, сформированные после создания последней резервной копии. Копии резервных копий баз данных также хранятся в удаленном ЦОД или облаке в целях архивации и для аварийного восстановления в случае аварии в основном ЦОД.
Уровень Bronze состоит из основных компонентов, описанных в следующих разделах.
Высокая доступность и защита данных в Oracle Database На уровне Bronze используются следующие средства высокой доступности и защиты данных, включенные в Oracle Database Enterprise Edition без дополнительной платы.
Oracle Restart автоматически перезапускает базу данных, Listener и другие компоненты »
Oracle после аппаратного или программного выхода из строя или каждый раз, когда перезапускается компьютер с базой данных.
Средства Oracle для защиты от повреждений проверяют наличие физических »
повреждений и логических внутриблоковых повреждений. Повреждения данных в оперативной памяти обнаруживаются и не попадают на диск. Во многих случаях они могут быть устранены автоматически. Дополнительные сведения см. в разделе Preventing, Detecting, and Repairing Block Corruption for the Oracle Database (Предотвращение, обнаружение и устранение поврежденных блоков для Oracle Database).
Automatic Storage Management (ASM) - интегрированная с Oracle файловая система »
4 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
и менеджер томов с автоматическим зеркалированием для защиты от выхода из строя диска.Oracle Flashback Technologies - группа функций, обеспечивающих быстрое исправление »
ошибок различного вида, необходимы для восстановления определенной транзакции, таблицы или всей базы данных.
Oracle Recovery Manager (RMAN) обеспечивает экономичное и надежное резервное »
копирование и восстановление, оптимизированное для Oracle Database.
Online Maintenance - функция, которая включает переопределение и реорганизацию »
данных без остановки для технического обслуживания баз данных, переноса файлов и патчирования.
Консолидация баз данных на уровне Bronze Базы данных, развернутые на уровне Bronze, включают базы данных для разработки и тестирования, а также для небольших рабочих групп и приложений отдельных подразделений, которые часто являются первыми кандидатами на консолидацию баз данных и предоставление базы данных как сервис (DBaaS).
Oracle Multitenant - методология MAA для консолидации и виртуализации баз данных, начиная с версии Oracle Database 12c. Другие опции консолидации включают следующее.
Виртуализация операционной системы - несколько виртуальных машин на одной физической хост-машине »
Консолидация схем - разные схемы приложений в одной базе данных »
Консолидация платформ - несколько отдельных баз данных на одной физической машине или в одном »
кластере Oracle RAC Компромиссы между Oracle Multitenant и другими методами консолидации обсуждаются в технической статье по Архитектуре Максимальной Доступности Oracle (Oracle Maximum Availability Architecture) «High Availability Best Practices for Database Consolidation» (Лучшие практики высокой доступности для консолидации баз данных).
Управление жизненным циклом и предоставление базы данных как сервис (DBaaS) Oracle Enterprise Manager Cloud Control - обеспечивает развертывание ИТ-ресурсов пользователями самостоятельно согласно модели пулов ресурсов для разных мультиарендных архитектур. Эти возможности необходимы для внедрения подхода DBaaS (база данных как сервис) - парадигмы, в которой конечные пользователи (АБД, разработчики приложений, инженеры по качеству обслуживания, руководители проектов и т. д.) могут запрашивать сервис баз данных, использовать их в течение жизненного цикла проекта, а затем освободить их и вернуть в пул ресурсов. С помощью Cloud Control Database as a Service (DBaaS) обеспечивается следующее.
Общая консолидированная платформа для предоставления сервиса базы данных »
Модель самообслуживания для развертывания этих ресурсов »
Гибкое увеличение и уменьшение ресурсов базы данных »
Взимание платы только за использованные ресурсы БД »
Комплексы Oracle Engineered Systems Комплексы Oracle Engineered Systems снижают расходы в течение всего жизненного цикла за счет стандартизации на предынтегрированной и оптимизированной платформе для СУБД Oracle Database и приложений. Комплексы Oracle Engineered Systems включают следующее.
Oracle Virtual Compute Appliance - кардинально упрощает для заказчиков установку и развертывание »
виртуальных инфраструктур для любого приложения Linux, Oracle Solaris или Microsoft Windows, а также управление ими.
Oracle Database Appliance - недорогой комплексный пакет программного обеспечения, систем хранения »
данных, серверных и сетевых средств, который снижает сложность и экономит время и деньги, упрощая
5 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
развертывание, техническое обслуживание и поддержку баз данных и приложений. Oracle Database Appliance поддерживает как физические, так и виртуальные развертывания.Программно-аппаратный комплекс Oracle Exadata Database Machine - самая высокопроизводительная, »
масштабируемая и доступная платформа для работы Oracle Database. Oracle Exadata Database Machine работает с приложениями любых типов, включая оперативную обработку транзакций (OLTP), хранилища данных (DW) и консолидацию приложений смешанного типа нагрузки, что создает идеальную основу для консолидации баз данных.
Oracle SuperCluster - специализированные системы, идеальные для консолидации баз данных и »
приложений, развертываний в частном облаке и использования программного обеспечения Oracle на единой универсальной платформе. Oracle SuperCluster использует самые быстрые процессоры в мире на основе архитектуры SPARC и системы хранения Exadata.
Oracle ZFS Storage Appliance обеспечивает немедленные преимущества экономии дискового »
пространства, управления и экономии средств для заказчиков, используюя сетевую систему хранения (NAS). Oracle ZFS включает многофункциональный пакет ПО для управления, мониторинга, устранения неисправностей, моментальных копий, клонирования, тиражирования и дополнительные сервисы хранения данных, естественно дополняя все системы Oracle Engineered Systems.
Заключение по уровню Bronze: защита данных, RTO и RPO В таблице ниже суммируются все возможности защиты данных уровня Bronze. В первом столбце таблицы 2 указано, когда выполняются проверки на наличие физического и логического повреждения данных.
Ручные проверки инициируются администратором или через регулярные интервалы времени »
плановым заданием, выполняющим периодические проверки.
Проверки на лету постоянно выполняются фоновыми процессами, когда база данных открыта.
Фоновые проверки выполняются через заданные регулярные интервалы времени, но только в »
периоды, когда ресурсы не используются.
Каждая проверка уникальна для Oracle Database и использует специальные знания структуры блоков данных Oracle и журналов базы данных.
ЗАЩИТА ДАННЫХ BRONZE
– – –
Обратите внимание, что проверка HARD и функция Automatic Hard Disk Scrub and Repair уникальны для системы хранения Exadata. Благодаря проверке HARD СУБД Oracle Database не записывает физически поврежденные блоки на диск. Automatic Hard Disk Scrub and Repair периодически определяет и восстанавливает жесткие диски с поврежденными или изношенными секторами (кластер системы хранения), а также обнаруживает и устраняет другие физические и логические дефекты, когда есть свободные ресурсы.
Exadata посылает запрос в ASM на восстановление поврежденных секторов путем считывания данных из другой зеркальной копии. По умолчанию очистка диска (scrub) выполняется каждые две недели.
6 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
В следующей таблице показаны RTO и RPO уровня Bronze для различных плановых и внеплановых простоев.ВРЕМЯ ВОССТАНОВЛЕНИЯ (RTO) И ВОЗМОЖНАЯ ПОТЕРЯ ДАННЫХ (RPO) НА УРОВНЕ BRONZE
– – –
Silver: высокая доступность с автоматическим переключением на резерв Уровень Silver основан на уровне Bronze, но включает технологию кластеризации для повышенной доступности во время внеплановых простоев и планового обслуживания (рис. 4). Уровень Silver использует технологию кластеризации Oracle RAC или Oracle RAC One Node для обеспечения высокой доступности в ЦОД. Это достигается путем автоматического переключения на резерв в случае отключения одного из экземпляров базы данных или в случае полного выхода из строя сервера, на котором работает экземпляр базы данных. Oracle RAC дает еще одно существенное преимущество - устраняет различные типы плановых простоев благодаря возможности техническому обслуживания узлов кластера Oracle RAC поочередно Уровень Silver: высокая доступность с быстрым переключением на резерв RTO за секунды в случае выхода сервера из строя, RPO со времени последнего резервного копирования Рис. 4. Эталонная архитектура высокой доступности Silver
7 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Уровень Silver включает компоненты высокой доступности, описанные в следующих разделах.Oracle Real Application Clusters (Oracle RAC) Oracle RAC повышает доступность приложения внутри ЦОД в случае отказа экземпляра базы данных или сервера, на котором работает экземпляр. Переключение на резервный сервер с Oracle RAC происходит мгновенно. Время восстановления сервиса на оставшихся экземплярах и повторного подключения пользователей отказавшего узла практически незаметно.
Также исключаются простои для задач планового обслуживания, которые могут выполняться поочередно для всех узлов Oracle RAC. Пользователи завершают свою работу и закрывают свои сессии на узле, где будет проводиться обслуживание. При повторном подключении они получают доступ к экземпляру базы данных, уже работающему на другом узле.
Краткий обзор того, как работает кластер Oracle RAC, помогает понять его преимущества. Существует два компонента: экземпляры Oracle Database и сама СУБД Oracle Database.
Экземпляр базы данных определяется как набор серверных процессов и структур памяти, которые работают »
на одном узле (или сервере) и делают конкретную базу данных доступной для клиентов.
База данных - определенный набор файлов с общим доступом (файлы данных, индексные файлы, »
управляющие файлы и файл инициализации), которые хранятся на диске и вместе могут открываться и использоваться для чтения и записи данных.
Oracle RAC использует архитектуру «активный-активный», в которой может быть несколько экземпляров баз »
данных, работающих на разных узлах, для одновременного чтения и записи данных в одной и той же базе данных.
Архитектура «активный-активный» кластера Oracle RAC обеспечивает следующие преимущества.
Повышение уровня высокой доступности. Отказ сервера или экземпляра базы данных не затрагивает »
подключения к остальным экземплярам, а подключения к отказавшему экземпляру быстро переносятся на другие экземпляры, которые уже работают и открыты на других серверах кластера.
Масштабируемость. Кластер Oracle RAC идеален для приложений и консолидированных сред, где »
требуется масштабируемость и возможность динамически добавлять вычислительную мощности и менять их приоритеты на более чем одном сервере. Одна база данных может иметь экземпляры, работающие на одном или нескольких узлах кластера. Точно так же один и тот же сервис базы данных может быть доступен на одном или нескольких экземплярах базы данных. Дополнительные узлы, экземпляры баз данных и сервисы баз данных могут переопределяться без остановки кластера. Возможность легко распределять рабочие нагрузки по всему кластеру делает Oracle RAC идеальным дополнением к Oracle Multitenant.
Надежная производительность. Oracle Quality of Service (QoS) может использоваться для назначения »
ресурсов высокоприоритетным сервисам баз данных и обеспечения стабильно высокой производительности в консолидированных средах баз данных. Вычислительные мощности могут динамически перераспределяться для быстрой адаптации к меняющимся требованиям.
Высокая доступность во время планового обслуживания. Высокая доступность обеспечивается благодаря »
внесению изменений на узлах Oracle RAC поочередно. Это включает обслуживание оборудования, ОС или сети, когда сервер должен быть переведен в автономный режим, внесение патчей в программный стек Oracle Grid Infrastructure или базу данных, а также обслуживание, когда необходимо перенести экземпляр базы данных на другой сервер для повышения вычислительной мощности или распределения нагрузки.
Oracle RAC - лучшая практика MAA для обеспечения высокой доступности серверов.
Oracle RAC One Node Oracle RAC One Node обеспечивает альтернативу кластеру Oracle RAC на уровне Silver, когда высокая доступность сервера необходима, а масштабируемость и мгновенное переключение на резерв не требуются. Лицензия Oracle RAC One Node стоит вдвое дешевле, чем Oracle RAC, и является менее дорогой альтернативой, если в случае отказов серверов достаточно RTO в минутах.
8 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Oracle RAC One Node - технология переключения на резерв «активный-пассивный». Она основана на той же инфраструктуре, что и Oracle RAC, но в случае Oracle RAC One Node во время штатной работы в каждый момент времени открыт только один экземпляр базы данных.В случае отказа сервера, на котором размещена открытая база данных, Oracle RAC One Node автоматически запускает новый экземпляр базы данных на втором узле для быстрого возобновления сервиса.
Oracle RAC One Node имеет ряд преимуществ над другими технологиями кластеризации «активный-пассивный».
В конфигурации Oracle RAC One Node сервисы Oracle Database HA Services, инфраструктура Grid Infrastructure и прослушивающие процессы базы данных всегда работают на втором узле. Во время аварийного переключения на резерв требуется запуск только экземпляра базы данных и сервисов базы данных, что ускоряет возобновление обслуживания и дает возможность перезапустить службы за минуты.
Для планового обслуживания Oracle RAC One Node обеспечивает те же преимущества, что и Oracle RAC. В кластере RAC One Node в период планового технического обслуживания два активных экземпляра базы данных могут обеспечить плавную миграцию пользователей с одного узла на другой с нулевым временем простоя. Обслуживание узлов осуществляется в скользящем режиме, и в это время сервисы баз данных остаются доступными для пользователей.
Заключение по уровню Silver: защита данных, RTO и RPO Уровень защиты данных такой же, как на уровне Bronze. Улучшения на уровне Silver по сравнению с уровнем Bronze связаны с RTO в случае отказа сервера и с некоторыми, часто выполняемыми видами планового ТО. Области улучшения по сравнению с уровнем Bronze показаны жирным шрифтом в следующей таблице.
ВРЕМЯ ВОССТАНОВЛЕНИЕ (RTO) И ВОЗМОЖНЫЕ ПОТЕРИ ДАННЫХ (RPO) НА УРОВНЕ SILVER
– – –
Gold: комплексные возможности высокой доступности и защиты от сбоев Уровень Gold основан на уровне Silver, но использует технологию репликации баз данных для устранения единой точки отказа, который может вызвать выход из строя всей системы, а также для значительного повышения уровня защиты и доступности данных для всех типов внеплановых сбоев, включая повреждения данных, отказы баз данных и отказы ЦОД. Наличие тиражированной копии также значительно сокращает простои в периоды планового обслуживания. Общий вид уровня Gold показан на рис. 5.
9 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
RTO снижается до секунд или минут, а RPO - до нуля или почти до нуля в зависимости от конфигурации.Уровень Gold: комплексные возможности высокой доступности и защиты от сбоев RTO от секунд до минут, RPO до нуля или почти до нуля Рис. 5. Эталонная архитектура высокой доступности Gold Обратите внимание, что уровень Gold использует Oracle RAC как стандарт для высокой доступности серверов вместо менее функционального Oracle RAC One Node, доступного на уровне Silver.
Уровень Gold добавляет компоненты для более высоких уровней обслуживания, описанных в следующих разделах.
Oracle Active Data Guard - защита данных в реальном времени и высокая доступность Oracle Active Data Guard поддерживает одну или несколько синхронизированных физических реплик (резервных баз данных) на удаленном узле для устранения единой точки отказа, которой мог бы привести к выходу из строя основной базы данных. Основываясь на лучших практиках MAA, предлагается использовать одну и ту же конфигурацию для основной и резервной баз данных (ЦП, память, ввод-вывод и т. д.), чтобы резервная база данных после аварийного переключения на нее могла обеспечить ту же производительность, что и исходная основная.
Active Data Guard добавляет следующие возможности на уровне Gold.
Выбор защиты для нулевой или практически нулевой потери данных. Active Data Guard выполняет »
репликацию изменений из основной базы в резервную в реальном времени. Изменения передаются непосредственно из журнального буфера основной базы данных, чтобы свести к минимуму задержки репликации и влияние на основную БД, а также для полной изоляции процесса репликации от повреждений, которые могут возникнуть в стеке ввода-вывода производственной базы данных.
Администраторы могут выбрать синхронную передачу в режиме защиты Maximum Availability (Максимальная »
доступность) для гарантии нулевой потери данных. Или они могут выбрать асинхронную передачу в режиме Maximum Performance (Максимальная производительность) с почти нулевой потерей данных. Режим Maximum Performance может ограничить возможность потери данных интервалом менее одной секунды, если пропускная способность сети достаточна для размера реплицируемых данных.
Data Guard и Active Data Guard - это единственные технологии репликации Oracle, обеспечивающие защиту »
с нулевой потерей данных.
Резервная база данных Oracle Active Data Guard может быстро принять на себя производственную нагрузку »
и восстановить сервис, если из-за отказа базы данных или отключения вычислительной площадки основная база данных становится недоступной. СУБД Oracle Database всегда работает, ее не нужно перезапускать, и передача роли основной БД может завершиться менее чем за 60 секунд даже в сильно загруженных системах.
10 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Уровень Gold использует функцию Data Guard Fast-Start Failover для автоматического аварийного переключения »базы данных на резерв. Это ускоряет восстановление, устраняя задержку на уведомление администратора, чтобы он мог среагировать на сбой. Fast Start Failover использует ролевые сервисы базы данных и технологию уведомления клиентов Oracle, чтобы приложения могли быстро отключиться от отказавшей основной БД и автоматически подключиться к новой основной. Передача роли БД может производиться вручную через интерфейс командной строки или Oracle Enterprise Manager.
Прозрачная репликация. Data Guard и Active Data Guard выполняют полную, одностороннюю физическую »
репликацию СУБД Oracle Database со следующими характеристиками: высокая производительность, простота управления, поддержка всех типов данных, приложений и видов нагрузок, таких как DML, DDL, OLTP, пакетная обработка и хранилище данных, а также консолидированные базы данных. Data Guard и Active Data Guard тесно интегрируются с технологиями Oracle RAC, ASM, RMAN и Oracle Flashback.
Перенос нагрузки с промышленной БД для большей окупаемости инвестиций. Резервные базы данных Oracle »
Active Data Guard могут быть открыты только для чтения, когда выполняется репликация. Обновленная, активная резервная БД идеальна для переноса на нее тяжелых SQL-запросов и отчетности с основной БД.
Это повышает окупаемость резервных систем и производительность основной БД благодаря использованию вычислительных мощностей, которые иначе бы простаивали. Проводится также постоянная проверка приложений, чтобы резервные базы данных были готовы принять нагрузку в случае отключения основной базы данных.
Освобождение основной БД от задач резервного копирования. Основная и резервная системы являются »
точными физическими копиями друг друга, что позволяет перенести задачи резервного копирования с основной БД на резервную. Резервная копия, созданная на резервной БД, может использоваться для восстановления основной или резервной БД. Это предоставляет администраторам гибкость процесса восстановления, а производственным системам не нужно нести бремя резервного копирования.
Снижение простоев для планового обслуживания. Резервные БД могут использоваться для обновления на »
новый патчсет (например, патч для перехода с версии 11.2.0.2 на 11.2.0.4) или для перехода на новую версию Oracle (например, с 11.2 на 12.1) поочередно: сначала обновляется резервная база данных, после чего она становится производственной уже с новой версией. Общее время простоя снижается до времени передачи роли основной базы данных резервной базе данных и времени переключения пользователей на новую основную базу данных после окончания обновления.
Резервная база данных Oracle Active Data Guard выполняет постоянную проверку данных, чтобы никакие »
повреждения не могли быть скопированы из исходной базы данных. Oracle Active Data Guard обнаруживает физические и логические повреждения блоков, которые могут возникнуть в основной или резервной базе данных. Это также уникальное средство обнаружения повреждений блоков при записи (потерянных или потерявшихся операций записи, признанных успешными подсистемой ввода-вывода). Дополнительные сведения доступны в документе My Oracle Support Note 1302539.1 - Best Practices for Corruption Detection, Prevention, and Automatic Repair (Лучшие практики обнаружения, предотвращения и автоматического устранения повреждений блоков БД).
Автоматическое восстановление блоков. Oracle Active Data Guard автоматически устраняет повреждения на »
уровне блоков, вызванные случайными ошибками ввода-вывода, которые могут возникнуть как на основной, так и резервной БД. Это делается путем извлечения хорошей копии блока из противоположной БД. Никакие изменения в приложениях не требуются, и исправление происходит незаметно для пользователей.
Вышеуказанное также объясняет, почему уровень Gold использует технологию репликации для поддержания синхронизированной копии, а не продукты удаленного зеркалирования системы хранения (SRDF, Hitachi TrueCopy и т. д.). Дополнительные сведения об этих различиях см. в разделе Oracle Active Data Guard vs. Storage Remote Mirroring (Сравнение Oracle Active Data Guard и удаленного зеркалирования системы хранения).
Oracle GoldenGate Программное обеспечение Oracle GoldenGate обеспечивает логическую репликацию для поддержания синхронизированной копии (целевая база данных) основной базы данных (исходная база данных). Oracle GoldenGate считывает изменения с диска исходной базы данных, переводит данные в файловый формат, независимый от платформы, передает файл в целевую базу данных и затем превращает данные в операторы SQL (обновления, вставки и удаления), нативные для целевой базы данных. Целевая БД содержит те же данные, но это уже не исходная, а другая БД (например, резервные копии не взаимозаменяемы). Логическая репликация - это более
11 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
сложный процесс, чем физическая репликация, но она дает больше гибкости для различных сценариев репликации и для разнородных платформ.С точки зрения распределения данных логическая репликация предназначена для экономичной »
репликации подмножеств исходной БД с целью распространения данных на другие целевые БД. Она также может использоваться для консолидации данных из нескольких исходных БД в одну целевую БД (например, Operational Data Store).
С точки зрения высокой доступности логическая репликация может использоваться для поддержания »
полной реплики исходной БД для высокой доступности или защиты от сбоев, переключение на резервную БД может выполнено немедленно.
Логическая репликация Oracle GoldenGate позволяет гибко проводить техническое обслуживание и »
миграцию поочередно, когда с репликацией Data Guard это невозможно. Например, Oracle GoldenGate обеспечивает репликацию из исходной БД на платформе, использующей порядок байтов big-endian в целевую БД на платформе с little-endian (cross-endian репликация). Это позволяет получить дополнительное преимущество от миграции с платформы на платформу: можно изменить направление репликации на обратное для быстрого возврата к предыдущей версии после перехода.
Логическая репликация Oracle GoldenGate - более сложный процесс с большим числом предварительных требований, чем у Data Guard. Но это компенсируется уникальными способностями Oracle GoldenGate обеспечить современные виды репликации. Документ MAA Best Practices: Oracle Active Data Guard and Oracle GoldenGate (Лучшие практики MAA: Oracle Active Data Guard и Oracle GoldenGate) содержит дополнительные сведения для выбора оптимальной технологии репликации или использования обеих технологий как дополняющих друг друга.
Oracle Site Guard Oracle Site Guard дает возможность администраторам координировать как плановые, так и внеплановые переключения (в случае непредвиденного отключения основного ресурса) целиком окружения Oracle (несколько баз данных и приложений) между производственным сайтом и удаленным. Oracle Site Guard входит в пакет Oracle Enterprise Manager Life-Cycle Management Pack.
Oracle Site Guard дает следующие преимущества.
Снижения числа ошибок благодаря готовой реакции на выход из строя узла. Oracle Site Guard »
снижает вероятность человеческих ошибок в случае аварий. Стратегии восстановления разрабатываются, тестируются и проходят проверку на отказ в рамках приложения. Если администратор инициирует операцию Site Guard для восстановления при катастрофических сбоях, участие человека не требуется.
Координация множества приложений, баз данных и различных технологий репликации. Oracle Site »
Guard автоматически обрабатывает зависимости между разными компонентами при запуске или остановке сайта.
Site Guard интегрируется с Oracle Active Data Guard для координации одновременных аварийных переключений нескольких баз данных на резерв. Site Guard также обеспечивает простой механизм интеграции любого продукта для удаленного зеркалирования системы хранения. Это ПО интегрируется с устройствами хранения для планового или аварийного переключения ресурсов на резерв. Для этого вызываются определенные сценарии передачи ролей для систем хранения.
Ускорение восстановления. Автоматизация Oracle Site Guard сводит к минимуму ручную »
координацию операций восстановления. Это ускоряет восстановление даже по сравнению со случаем, когда все ручные операции выполняются успешно. Site Guard экономит время и благодаря тому, что не приходится устранять последствия человеческих ошибок, часто возникающих при выполнении сложных процедур вручную.
12 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Заключение по уровню Gold: защита данных, RTO и RPO В следующей таблице показаны возможности защиты данных, RTO и RPO уровня Gold.Области улучшений выделены жирным шрифтом.
ЗАЩИТА ДАННЫХ УРОВНЯ GOLD
– – –
13 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Platinum: отсутствие простоев для приложений, готовых к уровню сервиса Platinum Уровень Platinum основан на уровне Gold и обеспечивает высокий уровень доступности и защиты данных для приложений, где отключения или потери данных абсолютно недопустимы. Уровень Platinum предоставляет несколько новых возможностей Oracle Database 12c, а также ранее доступные продукты, расширенные в новой версии.Platinum делает отключения незаметными для приложения и пользователей, и даже транзакции, выполняемые в момент отключения, повторяются на лету после восстановления. Время простоя для технического обслуживания, миграций и обновления приложений равно нулю. Гарантируется нулевая потеря данных в случае выхода из строя основной БД по любой причине, независимо от расстояния между основным и резервным узлами. Уровень Platinum также автоматически управляет доступностью сервисов базы данных и балансировкой нагрузки между репликами на нескольких узлах. Общий вид уровня Platinum показан на рис. 6.
Уровень Platinum Отсутствие простоев для приложений, готовых к уровню сервиса Platinum
– – –
Рис. 6. Эталонная архитектура высокой доступности Platinum Для полного исключения простоев на уровне Platinum многим приложениям потребуются незначительные изменения. Вот почему мы говорим, что уровень Platinum обеспечивает нулевое время простоя только приложениям, готовым к уровню Platinum. Обратите внимание, что для нулевой потери данных никакие изменения в приложениях не требуются.
На уровне Platinum используются средства обеспечения высокой доступности, описанные в следующих разделах.
Технология Application Continuity Технология Application Continuity защищает приложения от прерывания сессий базы данных из-за выхода из строя экземпляра, сервера, системы хранения, сети, любого другого компонента и даже всей базы данных. Технология Application Continuity повторяет транзакции, выполняемые в момент отключения, для приложения это просто небольшая задержка выполнения, незаметная для пользователя.
В случае отказа всего кластера Oracle RAC, когда база данных становится недоступной, технология Application Continuity воспроизводит сеанс, в том числе нужную транзакцию, после аварийного переключения на резервной БД с помощью Oracle Active Data Guard. Для использования технологии Application Continuity с резервной базой данных требуется режим Data Guard Maximum Availability и Data Guard Fast Start Failover.
14 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Oracle Active Data Guard Far Sync Data Guard и Active Data Guard - это единственные технологии репликации для работы с Oracle, которые обеспечивают аварийное переключение с нулевой потерей данных для СУБД Oracle Database. Нулевая потеря данных достигается с помощью синхронной передачи в режиме Data Guard Maximum Availability. Если используется синхронная передача, то время ожидания в сети при передачи данных между основным и резервным узлами влияет на производительность базы данных. Чем больше расстояние между узлами, тем больше время ожидания и его влияние на производительность БД. Поскольку основной и резервный ЦОД часто находятся на большом расстоянии друг от друга, выбор нулевой потери данных непрактичен для многих баз данных.Active Data Guard Far Sync устраняет вышеуказанные ограничения, обеспечивая нулевую потерю данных без ухудшения производительности основной базы данных даже в случае, если основная и резервная базы данных находятся в сотнях и даже тысячах километров друг от друга. Это достигается с помощью «легкого» механизма передачи, простого в развертывании и прозрачного для операций аварийного переключения Oracle Active Data Guard или планового переключения. Если Far Sync используется с опцией Oracle Advanced Compression Option, обеспечивается также сжатие данных для передачи за пределы основного сайта для экономии пропускной способности сети.
Если технология Application Continuity используется вместе с Far Sync в режиме Data Guard Fast-Start-Failover (автоматическим аварийным переключением на резерв), она может сделать отключения незаметными для транзакций, выполнявшихся в этот момент, независимо от расстояния между основным и резервным узлами.
Таким образом, Far Sync обеспечивает два основных дополнительных преимущества уровня Platinum: аварийное переключение на резерв без потери данных для любой базы данных и возможность использовать технологию Application Continuity независимо от расстояния между узлами. Active Data Guard Far Sync - новый режим в Oracle Database 12c. Для использования преимуществ Far Sync никакие изменения в приложениях не требуются.
Техническое обслуживание без простоев с помощью GoldenGate и репликация «активный-активный»
Уровень Platinum использует передовые свойства репликации Oracle GoldenGate для технического обслуживания без простоев и для миграций с помощью двусторонней репликации. Рассмотрим следующий сценарий.
Техническое обслуживание сначала выполняется на целевой БД.
Исходная и целевая БД синхронизируются для разных версий БД, использующих логическую репликацию »
Oracle GoldenGate. Это обеспечивает миграции между платформами с прямым и обратным порядком байтов (cross-endian). Это также обеспечивает сложные обновления приложений, которые изменяют серверные объекты, где механизм репликации должен преобразовать данные из старой версии в новую или наоборот.
Когда новая версия платформы стабилизирована и стабильна, двусторонняя репликация дает возможность »
пользователям постепенно и без простоев перейти на новую платформу по мере завершения сессий в прежней версии и подключения к новой. Двусторонняя репликация Oracle GoldenGate поддерживает синхронизацию старой и новой версий во время миграции. Это также позволяет быстро вернуться к старой версии, если возникнут неожиданные проблемы с новой версией по мере добавления нагрузки.
Двусторонняя репликация «активный-активный» может также использоваться для повышения уровней доступности сервиса, когда требуется постоянное подключение к нескольким копиям одних и тех же данных для чтения и записи.
Двусторонняя репликация непрозрачна для приложения. Требуется обнаружение и разрешение конфликтов, когда изменения одновременно вносятся в одну и ту же запись в нескольких БД. Необходимо также учитывать влияние разных видов сбоев и задержки репликации. Если двусторонняя репликация GoldenGate используется для обновлений приложения, изменяющих серверные объекты БД, для репликации между разными версиями требуется на уровне разработчика знание объектов БД, изменяемых или добавляемых в новой версии. Для каждой новой версии приложения требуется сопоставление версий.
15 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Репликация GoldenGate - это асинхронный процесс, не способный обеспечить нулевую потерю данных. Поэтому на уровне Platinum не используется Oracle GoldenGate для репликации между узлами, если удаленная реплика должна исключить потери данных в случае внепланового отключения основной базы данных или основного сайта.Для удовлетворения требования нулевой потери данных уровень Platinum использует двустороннюю репликацию GoldenGate в сочетании с Oracle Active Data Guard.
Локальная реплика GoldenGate используется для планового технического обслуживания без потери данных, а резерв Oracle Active Data Guard стабильно исключает потери данных при аварийном переключении в случае внепланового отключения во время обслуживания.
Функция Edition Based Redefinition Edition-Based Redefinition (EBR) обеспечивает обновления приложения, которые изменяют серверные объекты БД, в сети без нарушения доступности приложения. Когда установка обновлений завершена, старый и обновленный варианты приложения могут использоваться одновременно. Существующие сессии могут продолжать использовать приложение, каким оно было до обновления, пока пользователи не решат прекратить работу, а новые сессии могут использовать уже новую редакцию. Когда сессий, использующих необновленное приложение, не останется, его можно вывести из эксплуатации.
EBR позволяет обновлять приложения в интерактивном режиме следующим образом.
Изменения программного кода вводятся в новой редакции.
Изменения в данных вводятся безопасным способом путем записи только в новые столбцы или новые »
таблицы, невидимые для старой редакции. В специальном представлении редакций (editioning view) таблица отображается особым образом для каждой редакции, чтобы каждая редакция видела только свои столбцы.
Сross-edition распространяет изменения данных, произведенные в старом приложении, на столбцы »
обновленного приложения, и наоборот.
Так же как и с беспростойным обновлением приложения с Oracle GoldenGate, для внедрения и использования EBR требуется глубокое знание приложения и значительные усилия разработчика. В отличие от Oracle GoldenGate для использования EBR достаточно разовой инвестиции. После этого можно использовать EBR для последующих версий приложения с минимальными усилиями. Уже доказана на практике возможность использования EBR для самых сложных приложений. Например, Oracle E-Business Suite 12.2 использует EBR для патчирования без остановки. Возможность EBR добавлена в СУБД Oracle Database без дополнительной платы.
Решение Oracle Global Data Services Oracle Global Data Services (GDS) - комплексное решение по автоматическому управлению нагрузкой для реплицированных БД, использующих Oracle Active Data Guard или Oracle GoldenGate. GDS обеспечивает более высокий коэффициент использования системы, а также более высокий уровень производительности, масштабируемости и доступности для реплицируемых БД.
GDS обеспечивает следующие возможности для набора реплицируемых БД:
– – –
16 | ЭТАЛОННЫЕ АРХИТЕКТУРЫ ORACLE MAA - ОСНОВА ПОДХОДА DBAAS (БАЗА ДАННЫХ КАК СЕРВИС)
Заключение по уровню Platinum: защита данных, RTO и RPO Уровень Platinum обеспечивает такую же защиту от повреждений, как уровень Gold. Различия между уровнями Platinum и Gold связаны со временем восстановления (RTO) и возможной потерей данных (RPO) для приложений, готовых к работе на уровне Platinum.RTO и RPO для уровня Platinum показаны в следующей таблице.
ВРЕМЯ ВОССТАНОВЛЕНИЯ (RTO) И ВОЗМОЖНАЯ ПОТЕРЯ ДАННЫХ (RPO) НА УРОВНЕ PLATINUM
– – –
Заключение Организациям требуются решения для соответствия всему набору требований по защите и доступности данных.
Лучшие практики Oracle MAA определяют четыре эталонные архитектуры высокой доступности:
BRONZE, SILVER, GOLD и PLATINUM. Каждая эталонная архитектура MAA использует оптимальный набор средств высокой доступности Oracle для надежного обеспечения нужного уровня обслуживания с наименьшими расходами и сложностью. Развертывание программных средств высокой доступности и защиты данных, интегрированных в Oracle, с помощью стандартного набора архитектур высокой доступности, использующих общую инфраструктуру, обеспечивает уникальное решение для поддержки подхода база данных как сервис (DBaaS) в публичных или частных облаках.
2017 www.сайт - «Бесплатная электронная библиотека - различные документы»
Материалы этого сайта размещены для ознакомления, все права принадлежат их авторам.
Если Вы не согласны с тем, что Ваш материал размещён на этом сайте, пожалуйста, напишите нам , мы в течении 1-2 рабочих дней удалим его.
Изменение взглядов бизнеса на предоставление ИТ-услуг приводит к необходимости внедрения процесса управления их доступностью.
В третьей версии ITIL-процессы управления доступностью и непрерывностью ИТ-услуг рассматриваются вместе (далее процесс). Важнейшими ключевым понятиями этого совместного процесса являются:
доступность - способность ИТ-услуги или ее компонентов выполнять свои функции в определенный период времени;
надежность - способность ИТ-услуги или ее компонентов выполнять заданные функции при определенных условиях эксплуатации;
восстанавливаемость - способность ИТ-услуги или ее компонентов к восстановлению своих эксплуатационных характеристик, утраченных частично или полностью в результате сбоя;
обслуживаемость - характеристика ИТ-компонентов, определяющая их расположение и параметры с целью обеспечения рациональности действий персонала при монтаже, транспортировке, профилактике и ремонте (данное понятие применяется по отношению к внешним поставщикам ИТ-услуг).
Бизнес имеет свое представление о необходимой ему доступности и стоимости ИТ-услуг, а потому целью процесса является обеспечение требуемого уровня доступности с соблюдением определенного уровня затрат. Для достижения этой цели процесс направлен на выполнение следующих задач:
Планирование и разработка ИТ-услуг с учетом требований бизнеса к уровню доступности;
Оптимизация доступности ИТ-услуг путем проведения эффективных с точки зрения затрат усовершенствований;
Сокращение количества и продолжительности инцидентов, влияющих на доступность ИТ-услуг.
В ходе решения этих задач фиксируются требования бизнеса к доступности ИТ-услуг и компонентов ИТ-инфраструктуры; разрабатываются необходимые отчеты; производится периодический пересмотр уровней доступности ИТ-услуг; формируется план доступности, определяющий приоритеты и отражающий мероприятия по улучшению доступности ИТ-услуг. Иначе говоря, процесс сводится к планированию предоставления ИТ-услуг, измерению уровня доступности и проведению мероприятий по его улучшению.
Планирование
При планировании производится формулирование требований бизнеса к доступности ИТ-услуг, разрабатываются критерии определения уровня доступности и допустимого времени простоя ИТ-услуг, а также рассматриваются некоторые аспекты информационной безопасности. Бизнес должен установить границу, определяющую доступность и недоступность ИТ-услуги, например допустимое время перерыва в оказании ИТ-услуги в случае сбоя в ИТ-инфраструктуре.
При проектировании доступности ИТ-услуг проводится анализ ИТ-инфраструктуры с целью определения наиболее уязвимых компонентов, не имеющих резерва и способных в случае сбоя оказать негативное влияние на предоставление ИТ-услуг. В терминологии ITIL подобные компоненты называются Single Point of Failure (SPOF), и для их определения используется метод «Анализ влияния сбоев компонентов инфраструктуры» (Component Failure Impact Analysis, CFIA). Данный метод применяется для оценки и прогнозирования воздействия отказов ИТ-компонентов на ИТ-услугу. Основные цели CFIA таковы:
Определение точек сбоев, влияющих на доступность;
Анализ влияния сбоя компонентов на бизнес и пользователей;
Определение взаимосвязи компонентов и персонала;
Определение времени восстановления компонентов;
Определение и документирование вариантов восстановления.
Для анализа рисков используется метод анализа и управления рисками (CCTA Risk Analysis and Management Method, CRAMM), в котором анализируются возможные угрозы и зависимости ИТ-компонентов, проводится оценка вероятности возникновения нестандартных ситуаций или чрезвычайных событий.
Для обеспечения требуемого уровня доступности возможно использование техники маскирования от негативного влияния из-за планового или незапланированного простоя компонента, дублирования ИТ-компонентов, а также применение средств повышения производительности компонента в случае увеличения нагрузки и т.д. В случаях, когда конкретные бизнес-функции имеют высокую зависимость от доступности ИТ-услуг, а потери деловой репутации от простоя рассматриваются как недопустимые, устанавливаются более высокие значения доступности определенных ИТ-услуг и выделяются дополнительные ресурсы.
Проектирование предоставления ИТ-услуг гарантирует, что заявленные требования к доступности будут выполнены, но это относится к стабильному, рабочему состоянию ИТ-услуг. Однако возможны и сбои, поэтому проводится также планирование восстановления ИТ-услуг, включающее в себя организацию взаимодействия с процессом управления инцидентами и службой Service Desk; планирование и внедрение систем мониторинга для обнаружения сбоев и своевременного оповещения о них; разработку требований по резервированию и восстановлению аппаратного и программного обеспечения и данных; разработку стратегии резервного копирования и восстановления; определение метрик восстановления и т.д.
Еще один аспект планирования - определение времени простоя. Все ИТ-компоненты должны быть объектами стратегии обслуживания. В зависимости от применяемых ИТ, критичности и важности поддерживаемых конкретным ИТ-компонентом бизнес-функций частота и уровень обслуживания могут различаться. В случае необходимости предоставления услуги в режиме 24х7 следует найти оптимальный баланс между требованиями по обслуживанию ИТ-компонентов и потерями для бизнеса от простоя услуги. Утвержденные расписания обслуживания должны быть зафиксированы в соглашениях об уровне обслуживания (Service Level Agreement, SLA).
Улучшение доступности ИТ-услуг
Зачем нужно улучшать доступность? Причин может быть множество: несоответствие качества ИТ-услуг требованиям SLA; нестабильность предоставления ИТ-услуг; тенденции к снижению уровня доступности ИТ-услуг; недопустимо большие сроки восстановления; запросы со стороны бизнеса на увеличение уровня доступности.
Улучшение доступности требует обоснованных дополнительных финансовых затрат, и для установления возможности улучшения ИТ-услуг используются определенные методы и технологии, среди них анализ дерева отказов (Fault Tree Analysis, FTA) и анализ системных простоев (Systems Outage Analysis, SOA).
Анализ дерева отказов определяет цепь событий, приводящих к отказу ИТ-компонента или ИТ-услуги. Графически дерево отказов (см. рис.) представляет собой последовательность событий, которая начинается с инициирующего события, сопровождаемого одним или несколькими функциональными событиями, и заканчивается финальным состоянием. В зависимости от событий, последовательности могут логически разветвляться.
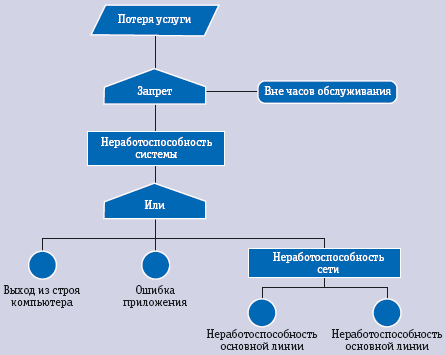
Анализ системных простоев представляет собой структурированный подход к идентификации основных причин прерывания в предоставлении ИТ-услуг и использует несколько источников данных для определения места и причины возникновения прерываний. Цели такого анализа:
Определение основных причин сбоев предоставления ИТ-услуг;
Определение эффективности поддержки ИТ-услуг;
Подготовка отчетов;
Инициирование программы по исполнению принятых рекомендаций;
Анализ улучшений уровня доступности, полученного с помощью анализа системных простоев.
Использование анализа системных простоев позволит повысить уровень доступности без увеличения затрат, улучшить собственные навыки персонала и способности, позволяющие избежать затрат на консультирование по вопросам улучшения доступности, определить конкретную программу улучшений.
Результатом деятельности по улучшению доступности услуг является долгосрочный план проактивного улучшения доступности ИТ-услуг с учетом финансовых ограничений. План доступности описывает текущие и запланированные уровни доступности, а также мероприятия, которые нужно проводить для ее улучшения. В подготовке плана необходимо участие представителей бизнеса, менеджеров внедренных процессов ITSM, представителей внешних поставщиков ИТ-услуг, технических специалистов поддержки, ответственных за тестирование и обслуживание. План составляется на срок до двух лет, а на ближайшие шесть месяцев он должен содержать подробное описание мероприятий. План пересматривается каждый квартал с минимальными корректировками и раз в полгода с возможностью внесения серьезных изменений.
Измерение доступности ИТ-услуг
ИТ-услуга с точки зрения потребителя может считаться доступной, когда жизненно важные функции бизнеса, ее использующие, выполняются нормально. При этом основными количественными показателями являются доступность - отношение времени реальной доступности ИТ-компонента ко времени доступности, определенному в соглашениях об уровне обслуживания, и недоступность (в %) - инверсия доступности. Эти параметры используются ИТ-службами и, с точки зрения бизнеса, не очень показательны, так как не отражают значения доступности для бизнеса или пользователей - они могут демонстрировать высокий уровень доступности ИТ-компонентов, в то время как актуальный уровень доступности ИТ-услуг будет низок.
Понятными бизнесу могут быть такие показатели, как: частота простоев ИТ-услуг, общая длительность простоя, область влияния от прерывания ИТ-услуги.
Роли и ответственности
В рамках процесса определяется роль менеджера процесса, в обязанности которого входит руководство процессом и выполнение необходимых действий. Менеджер процесса отвечает за функционирование и развитие процесса в соответствии с регламентирующими документами и планами. На роль менеджера процесса рекомендуется принимать сотрудника, имеющего практический опыт процессного управления, знающего ITSM, статистические и аналитические методы, применяемые в ИТ, принципы управления затратами, имеющего опыт работы с персоналом, владеющего методами проведения переговоров и т.д.
Внедрение процесса
Внедрение любого процесса ITSM - длительный и сложный проект, имеющий определенные цели и сроки. Внедрение собственными силами затруднительно: внедрение процесса параллельно с ежедневной операционной деятельностью не позволяет полностью сфокусироваться на проекте; постоянное «оттягивание» ресурсов на посторонние по отношению к проекту задачи в конечном результате приводит к росту финансовых затрат, сдвигу сроков проекта на неопределенный период, постепенной потере внимания или даже возможной остановке проекта. Кроме того, внедрение собственными силами требует знаний в данной предметной области, что влечет за собой необходимость проведения дорогостоящего обучения.
Как и любой проект, внедрение процесса начинается с создания проектных команд, разработки документов по управлению проектом, составления плана проекта и т.д. На этапе «предпроектных» работ проводятся маркетинговые мероприятия по ознакомлению представителей бизнеса с технологиями и рекомендациями ITIL и обоснованию необходимости для бизнеса внедрения процесса управления доступностью ИТ-услуг.
После согласования и получения положительного ответа о внедрении процесса определяются цели и границы предметной области процесса.
Эффект и проблемы
Основным эффектом от внедрения процесса является то, что ИТ-услуги разрабатываются с учетом требований к доступности, и их операционная деятельность и управление осуществляется на согласованном уровне доступности и в рамках определенных затрат. Положительными факторами также являются: наличие одного ответственного за доступность ИТ-услуг; оптимальное использование производительности ИТ-инфраструктуры для обеспечения требуемого уровня доступности ИТ-услуг; уменьшение частоты и длительности отказов ИТ-услуг с течением времени; качественный переход в деятельности поставщиков ИТ-услуг от устранения ошибок в предоставлении услуг к повышению уровня их доступности.
Возможные проблемы, которые могут негативным образом влиять на принятие решения о внедрении и функционировании процесса, обычно носят организационный характер:
Наличие ситуации, когда каждый ИТ-менеджер отвечает за доступность ИТ-систем или компонентов, находящихся в сфере его ответственности, в то время как общая доступность ИТ-услуг не отслеживается и может быть неудовлетворительной;
Отказ от внедрения процесса по причине того, что текущая доступность ИТ-услуг считается приемлемой;
Предположения, что при наличии других внедренных процессов ITSM процесс управления доступностью будет выполнен автоматически;
Сопротивление централизации в управлении ИТ-инфраструктурой со стороны ИТ-менеджеров;
Недостаточность полномочий менеджера процесса, приводящая к отсутствию возможности выполнения им обязанностей должным образом.
Евгений Булычев ([email protected]) - консультант отделения «Ай-Теко Бизнес Консалтинг» (Москва).
Идея написания этой статьи пришла после общения с одним из крупных заказчиков - коллега поведал историю выбора для своей компании провайдера облачных услуг IaaS.
Первый набор критериев для оценки сервис-провайдера выглядел примерно так: известное имя (бренд), положительная бизнес-история в области облачных услуг, адекватная стоимость. По результатам анализа возможных претендентов выбирали между несколькими компаниями, которые по вышеуказанным критериям были практически одинаковы и каждый старался доказать свои преимущества, ссылаясь на различные характеристики своих облачных услуг.
Владимир Курилов, компания «Онланта».
Так разговор дошёл до показателей надёжности. И вёлся он вокруг сравнения уровней доступности ЦОДов, в которых располагались облака. Достаточно быстро выяснилось, что только двое кандидатов располагают ЦОДами с уровнем доступности 99,98%. Выбор был сделан в пользу зарубежного провайдера облачных услуг - победила цена. Коллега объяснил всё просто, - «Какой смысл платить больше за те же самые показатели надёжности?»
Учитывая существование различных вариантов, давайте определимся с трактованием термина «Доступность» в рамках данной статьи. Определим доступность как время работоспособности системы в определённом интервале времени, выраженное в процентах к этому интервалу. Или в классическом виде: «Свойство объекта выполнять требуемую функцию при заданных условиях в течение заданного интервала времени». Что, в общем, ближе к уже достаточно устоявшемуся понятию «Готовность» системы.
Последовавший за этим решением год эксплуатации, показал, что у провайдера имеют место небольшие сбои в работе инженерных систем ЦОДа, при плановых переключениях. При этом доступность ЦОД оставалась в пределах SLA, так как переключение занимало секунды. Однако, если информационная система заказчика не останавливалась заранее перед такими переключениям, то база данных при сбоях требовала восстановления из резервной копии, что останавливало работу сотрудников на несколько часов. Выключение/включение систем, перед переключениями, немного поправляло ситуацию, но и при этом имел место простой сотрудников 25-30 минут, что тоже вызывало нарекания пользователей.
Прошёл год и теперь Коллега арендует мощности в другом облаке, где доступность одного из ЦОДов ниже вышеприведённой, а время простоев существенно уменьшилось. Как можно этого добиться и что важно при оценке надёжности работы облачных решений, а что не очень важно? Какие есть возможности экономии, снижения рисков переплаты «за красивые цифры», а не за фактическую надёжность? Как выделить критичные параметры облачных сервисов для надёжности работы Вашего приложения?
Ответы на эти вопросы я и попробую сформулировать далее.
Надёжность приложения - из чего она складывается в облаке
Надёжность сервиса приложения
Если попробовать сформулировать определение надёжности работы приложения, то оно будет звучать так: «Надёжность - это свойство приложения сохранять во времени работоспособность со всей функциональностью в него заложенной».
От чего зависит работоспособность приложения и, как надёжность приложения связана с доступностью ЦОДа?
Приложение базируется на программной платформе, которая, в свою очередь, располагается на инфраструктурной платформе, использующая инженерную платформу, см. Рис. В совокупности представленные четыре уровня обеспечивают предоставление «Сервиса Приложения».

Рис. Упрощённый пример расчёта доступности Сервиса Приложения
Как видно из рисунка мы имеем дело с системой последовательных элементов, где отказ любого элемента приводит к отказу системы в целом.
Доступность такой системы (As) определяется как произведение показателей доступности всех элементов:
A i – доступность каждого последовательно соединённого компонента.
A s = 0,99995 0,99995 0,993 0998 ≈ 0,99091 или 99,091
Как видим, доступность Сервиса Приложения имеет значение, далёкое от доступности инженерной платформы ЦОДа. Можно пересчитать цифры доступности в значения простоя системы. Получается, несмотря на допустимый годовой простой инженерной платформы, в 1 час. 45 мин., для сервиса приложения годовой простой составит 86 ч. 22 мин.
Соответственно, высокий показатель доступности ЦОДа, не говорит о столь же высокой надёжности сервисов приложений, работающих в этом ЦОДе.
Надёжность сетевого приложения
Следовательно, при выборе сервис-провайдеров правильно было бы ориентироваться на совокупную доступность сервисов приложений? К сожалению, тут не всё так просто.
Оказывается, разработчик ПО способен влиять на обеспечение надёжности (устойчивости к сбоям, нагрузкам) отдельно взятого приложения. Например, надёжность работы приложения в облаке может быть значительна улучшена за счёт применения специализированных библиотек, ориентированных на обработку задержек выполняемых запросов. Приложения же написанные стандартными способами, будут обладать сравнительно более низкими показателями надёжности.
Один из вариантов реализации применения специализированных библиотек компанией Microsoft - Transient Fault Handling Application Block (см. http://msdn.microsoft.com/en-us/library/hh680934(v=pandp.50).aspx).
Надёжность программной платформы
Надёжность программной платформы, включающей операционную систему, драйверы, библиотеки, опять же, остаётся «на стороне разработчиков» и, пока, не сильно зависит от сервис-провайдера. Однако, если сервис-провайдер продумал политику правильной технической поддержки, то это может косвенно влиять на доступность.
Я говорю о «гигиенических» средствах безопасности. В первую очередь, о сервисе обновления системного программного обеспечения. Он должен быть в портфеле услуг сервис-провайдера, а ещё лучше - учтён в цене услуги «по умолчанию». Во вторую очередь, это сервис антивирусной защиты с возможностью выбора антивирусных программ. И, в третьих, резервное копирование виртуальных серверов заказчика. Это не всё, но самые важные способы, позволяющие повысить доступность вашего Сервиса Приложения.
Надёжность инфраструктурной платформы
Эта составляющая надёжности полностью зависит от сервис-провайдера и должна оцениваться Вами наравне с доступностью инженерной платформы ЦОДа. Необходимо запросить этот параметр у провайдера, поскольку как правило он не указывается в маркетинговых материалах. При этом необходимо получить разъяснения - как этот параметр рассчитывался.
Хотя надо иметь в виду, что такие данные не все сервис-провайдеры захотят представить, поскольку из расчёта становится понятна структурная схема инфраструктурного решения и используемое оборудование - а это определённое ноу-хау.
Тем не менее:
- Попросите схему функциональной структуры инфраструктурной платформы для размещения именно Вашего Сервиса приложения. Она должна включать:
- Сетевую инфраструктуры;
- Сеть хранения данных;
- Вычислительную инфраструктуру.
- Попросите указать в этой схеме места резервирования оборудования. Указывать тип используемого оборудования нет необходимости.
- Попросите указать доступность (или готовность) для каждого уровня.
- Посчитайте доступность как произведение доступностей элементов инфраструктурной платформы.
Теперь у Вас есть возможность максимально достоверно определить доступность Вашего сервиса приложения. 90% СП в России, исходя из нашего опыта, имеют суммарную доступность не выше 99%. А это риск простоев до 87 часов в год. Это нормальные показатели доступности, если у Вас нет критических для бизнеса приложений, часовой простой которых приносит Вам миллионные убытки. А если часовая остановка сродни катастрофе для Вашего бизнеса, то для Вас есть оставшиеся 10%, СП, предоставляющие сервис корпоративного уровня с доступностью Сервиса приложения на уровне 99,99%. О том, какими способами это достигается в следующем разделе.
Решения, обеспечивающие высокую доступность сервиса приложения
Заказчику в итоге неважно как соблюдается SLA по инженерным системам, ему важно какова доступность сервиса его приложений, т.е. - гарантированное время восстановления работоспособности приложения.
Системы, которые мы ранее обсуждали, имели последовательную структуру. Доступность, которую мы посчитали выше как произведение отдельных элементов - это технический предел, обеспечиваемый подобными системами. На деле в силу появления различных дополнительных факторов доступность ещё ниже. Помните вначале статьи рассказ про секундное отключение электричества и пять часов простоя?
Есть ли возможность повысить доступность приложения, если параметры доступности конкретного ЦОДа заданы и изменить их нельзя?
Ответ - можно.
Вот, например, два подхода, которые позволяют это сделать:
- Географически распределённый кластер высокой доступности;
- Восстановление обработки в географически удалённом резервном центре обработки данных (Disaster recovery).

Рис. Структурная схема географически распределённого кластера высокой доступности

Рис. Структурная схема для восстановления обработки в географически удалённом резервном центре обработки данных
Первый подход идеален, с точки зрения доступности (восстановление работоспособности происходит за секунды), но проигрывает по цене и достаточно сложен в реализации. Второй подход осуществляет восстановление сервиса из рабочей копии - это не так оперативно и небольшую часть данных при сбое придётся восстанавливать вручную, но такой вариант имеет более низкую стоимость и проще в реализации.
В обоих случаях необходимо говорить о географической удалённости ЦОДов, чтобы максимально избежать возможности взаимосвязанных ресурсов. Например, использования одних и тех же подстанций, обеспечивающих электропитание ЦОДов. Можно вспомнить отключение электричества на юго-востоке г. Москва в мае 2008 года из-за пожара на Чагинской подстанции, New York 2003 год. Поэтому резервный ЦОД должен располагаться подальше от основного.
Подход с двумя ЦОДами позволяет говорить о создании системы с параллельными элементами. При этом, с одной стороны, основной и резервный ЦОДы, являются самостоятельными системами, с другой стороны являются общей платформой для сервиса приложения - неважно в каком ЦОДе в данный момент работает приложение, оно может перемещаться из одного ЦОДа в другой.
Принципиальное отличие параллельной системы в том, что надёжность растёт с увеличением параллельных элементов системы. Расчёт доступности системы, состоящей из параллельных элементов, можно производить по формуле:

Где: A s – Суммарная доступность, доступность всей системы,
A i – доступность каждого параллельно соединённого компонента.
Для примера, рассчитаем систему географически распределённого кластера высокой доступности из двух ЦОДов с доступностью = 99%, каждый.
A s = 1-(1-0,99)*(1-0,99)= 0,9999 или 99,99
Т.е., два не самых надёжных ЦОДа могут обеспечить доступность на уровне mission-critical систем.
Определить доступность сервиса приложения в варианте восстановления обработки в географически удалённом резервном центре обработки данных с 15 минутным интервалом синхронизации для случая единичного сбоя рассчитывается так: надо запросить время восстановления сервиса приложения, гарантируемое СП; далее считаем процент от годового интервала - и результат вычитаем из единицы. Получаем доступность после первого сбоя. Например, для системы с 15 минутным интервалом синхронизации:
Общее количество часов в году 365*24=8760
Гарантированное время простоя = Время максимального простоя
15 минут или 0,25 часа, что составляет ≈ 0,003 от годового времени
Т.е. каждый сбой будет иметь вес в 0,003%. Таким образом, система до сбоя система имеет доступность, равную 100%, после первого сбоя, 99,997%, после второго сбоя 99,994%. Посчитаем тоже самое для системы с часовым интервалом синхронизации:
Гарантированное время восстановления = Время максимального простоя = 1 час, что составляет ≈ 0,01 от годового времени
Каждый сбой будет иметь вес в 0,01%. Таким образом, система до сбоя система имеет доступность, равную 100%, после первого сбоя, 99,99%, после второго сбоя 99,98%. Дальше, приверженцы теории вероятности могут поупражняться в оценке вероятности наступления первого, второго, третьего сбоев. Результат убедит, что влияние этого фактора ничтожно мало на получаемые результаты. Это позволяет мне рекомендовать предложенную методику для оценки доступности сервисов для Ваших приложений в облаке .
Резюмируя вышесказанное...
- Начните с оценки бизнес-критичности приложения, планируемого к размещению в облаке. Оцените стоимость простоя приложения. Сколько Вам будет обходиться отсутствие сервиса приложения?
- Отсюда оцените допустимое значение простоя в день, в год. Посчитайте критическую доступность сервиса приложения.
- Сопоставьте возможные потери от простоя с ценами СП, которые предлагают приемлемую для ваших приложений доступность.
- При выборе СП, отдавайте предпочтение тому, кто может обеспечить не только текущий уровень доступности, но и как дополнительный сервис/услугу предоставить улучшение доступности. Особенно если Ваш бизнес растёт и развивается.
- И оставайтесь практиками. Берите то, что дают пощупать = потестировать. Теория без практики, не очень полезна для бизнеса.